Conference/Workshop Reports
FSTTCS 2011 Conference Report
I attended the FSTTCS conference that was held in IIT Bombay last December. The conference saw over 180 participants and had many interesting talks. I will discuss a few of them in this post.
Talks from Breakthroughs in TCS workshop
Madhu Sudan. Multiplicity Codes: Locality with High Efficiency.
Madhu Sudan gave a nice talk based on a recent result by Swastik Kopparty, Shubhangi Saraf and Sergey Yekhanin (STOC 2011). He was excited about the result for two reasons. Firstly, unlike other advances in LDCs where applications of the results are found only in other parts of theory, this result actually could be of great practical interest. “It’s the numbers that are making sense” he said. Secondly, the construction of the code is so elegant that you are surprised by its simplicity.
I’ll try to sketch the main idea below:
Background. Suppose we want to send a k-bit message on a noisy channel. A well-known method is to use an error-correcting code to encode the k-bit message x into an n-bit codeword C(x) and transmit the codeword instead of the message x. The codeword C(x) is such that we can recover the original message x from it even if many bits in C(x) get corrupted. A typical way to recover x would be to run a decoder on the (possibly corrupted) C(x).
Two parameters in this scheme are of interest: the redundancy incurred in constructing the codeword C(x) and the efficiency with which we can decode the message x from the codeword. The complexity of encoding is usually ignored since it is not critical in most applications.
The rate of the code is the ratio of message length to codeword length: k/n. The higher the rate, the lesser the redundancy of the code.
LDCs. But what if one is interested only in knowing just a particular bit of the message x? This is where a Locally Decodable Code (LDC) is useful. LDCs allow the reconstruction of any arbitrary bit xi by looking only at a small number of randomly chosen positions of the received codeword C(x). The query complexity of the code is the number of bits we need to look at in order to recover a particular bit.
Obviously, we desire to have LDCs with high rate and low query complexity. But until now, for codes with rate>1/2, it was unknown how to construct any non-trivial decoding. For rates lower than 1/2, we could construct a code with rate O(εΩ(1/ε)) and query complexity O( kε) for 0<ε<1. For example, Reed-Muller codes — which are based on evaluating multivariate polynomials.
Bivariate Reed-Muller codes. We briefly describe how polynomials can be useful in coding. Let Fq denote the finite field of cardinality q. Consider the bivariate polynomials over the field Fq. A bivariate polynomial of degree d has ( {d+1 \choose 2} ) monomials. For example, if d=2 the monomials are x2,xy and y2. So any polynomial of degree d can be specified by the coefficients of each of these monomials. The coordinates of the message x can be thought of as coefficients of a polynomial P(x,y) of degree d. So our message is of length ( k={d+1 \choose 2} ). Each coordinate of the message has a value from Fq (we call this an alphabet). The codeword C(x) corresponding to the message x is obtained as follows: The coordinates of the codeword is indexed by elements of ( F_{q}^2 ). So the length of the codeword n=q2.
The codeword corresponding to the polynomial P(x,y) is the vector C(P) as given below:
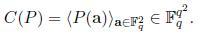
So the first co-ordinate of C(P) would have the value of P(1,1), the second coordinate would have the value of P(1,2), and in general the (i*q+j)th coordinate of C(P) would have the value P(i,j).
The rate of this code is less than 1/2 and it can be shown that the correct value at a particular coordinate of the received codeword can be decoded by making only O(√k) queries on the received codeword, assuming that a constant fraction of the codeword gets corrupted.
Multiplicity codes. The key idea in the paper is to encode the message using multivariate polynomials and their partial derivatives. If we plug this idea to the above example, each coordinate of the codeword will have 3 alphabets instead of one or in other words each coordinate would be a value from ( F_{q}^3 ). So the codeword is now:
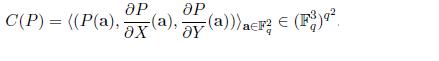
This improves the rate from <1/2 to 2/3! It can be done without increasing the query complexity. This by itself is a new result. What’s more is they can extend this idea to get codes of arbitrarily high rate while keeping the query complexity small. Here is their main theorem from the paper:
For every ε>0, α>0, and for infinitely many k, there exists a code which encodes k-bit messages with rate 1-α, and is locally decodable from some constant fraction of errors using O(kε) time and queries.
Umesh Vazirani. Certifiable Quantum Dice.
Background. Many computational tasks such as cryptography, game theoretic protocols, physical simulations, etc. require a source of independent random bits. But constructing a truly random device is a hard task. Even assuming that such a device is available, how do we test if it is working correctly? This task seems impossible since a perfect random number generator must output every n bit sequence with equal probability and there is no reason one can reject a particular output in favor of an other.
Quantum mechanics offers a way to get past this fundamental barrier: starting with O(log2 n) random bits one can generate n certifiable random bits.
To get an idea of how this is possible let us consider the CHSH game first (given below).
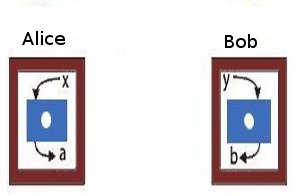 |
| The CHSH game. Alice and Bob are two co-operating players who receive inputs x and y, respectively from a third party. Alice and Bob are at two different locations. The winning condition for them is to produce outputs a and b such that the following condition is satisfied: If x=y=1, then a and b must be different. For any of the other three combinations of x and y, the outputs have to be equal. If the players are correlated according to the laws of classical physics, only any three of the four pairs of inputs can be satisfied. So the maximum probability of winning is 0.75. However, if they adopt a strategy based on quantum correlations, this value can be increased to 0.851. See the references in this article in Nature for more details. |
We can define a quantum regime corresponding to the success probabilities between 0.75 and 0.85. It is simple to construct two quantum devices corresponding to any value in the regime. But if two devices produce co-relations in the regime, they must be randomized. Or in other words, randomness is for real! This gives a simple statistical test to cerfify randomness.
Result. We are using two random input bits (x,y) to produce two random output bits, so this doesn’t accomplish much. We cannot claim the output to be more random than the input. Vazirani and Vidick in their paper describe a protocol that uses O(log 2 n) seed bits to produce n certifiable random bits.
Jaikumar Radhakrishnan. Communication Complexity of Multi-Party Set-Disjointness Problem.
Consider the following problem: Alice and Bob are given inputs x and y respectively and are asked to compute a function f(x,y). They are charged for the number of bits exchanged. The minimum number of bits that have to be exchanged in order to compute the function f is the communication complexity of the problem. A particular problem that is of interest in the area of communication complexity is the set-disjointness problem.
Problem. There are k parties each of whom has a subset from {1,..,n} stuck on his forehead. Each party can see the all the subsets except his own. The set-disjointness problem is to determine if the intersection of all the k subsets is empty. Again, we charge for the number of bits exchanged. All the parties have access to a shared blackboard on which they can write, so we have a broadcast medium.
The case when k=2 is well-understood both in both deterministic and randomized settings. (In randomized version, all the parties have access to a shared source of infinite random bits.)
Results. Until recently, for the general multi-party case, the best lower bound on communication complexity known for the number-on-the-forehead model was Ω(n1/k+1/2k^2). Last year, Sherstov improved this bound to Ω(n/4k)1/4 which is close to tight.
Jaikumar is a fantastic teacher. In what was basically a blackboard-talk, he gave an overview of the main ideas in Sherstov’s proof in a way that was accessible even to non communication-complexity experts. The arguments are based on approximating Boolean functions by polynomials.
Other talks in BTCS
There were several other good talks. Naveen Garg surveyed the recent progress on approximation algorithms for the Traveling Salesman Problem that achieve a strictly better than 1.5 approximation factor. Manindra presented the result on lower bound on ACC by Ryan Williams. Aleksender Madry gave two talks: one in which he presented a new randomized algorithm for the k-server problem that achieves poly-logarithmic competitiveness and one on approximating max-flow in capacitated, undirected graphs using the techniques from electrical flows and laplacian systems. Nisheeth Vishnoi discussed new algorithms for the Unique Games Conjecture. Amit Kumar gave a talk about a recent result by Friedman, Hansen and Zwick on proving lower bounds for randomized pivoting rules in simplex algorithm. Sanjeev Khanna spoke about some recent progress on the approximability of the edge-disjoint paths problem. Most of these results are now famous in theory-circles.
Conference talks
There were 38 papers out of which about 16 were from Theory A. Here are some of the talks I attended:
The Semi-stochastic Ski-rental Problem. (Aleksander Mądry and Debmalya Panigrahi)
An online algorithm is an algorithm which optimizes a given function when the entire input in not known in advance, but is rather revealed sequentially. The algorithm has to make irrevocable choices about the output as the input is seen. The ratio of the performance of the online algorithm to the optimal offline algorithm is called the competitive ratio of the algorithm.
On one hand, we have online models which assume nothing about the input and on the other we have stochastic models which assume that the input comes from a known distribution. The semi-stochastic model in this paper unifies these two extremes. In this model, the algorithm does not know the input distribution initially, but can learn the distribution by asking queries. The algorithm has a certain query budget. If the budget is zero (resp. infinite), the model reduces to the online (resp. stochastic) version. The goal is to maximize the competitive ratio assuming that the queries are answered adversarially.
This model is well-motivated because in many real world situations, the online model is too pessimistic and the stochastic model is too optimistic. We can usually learn the input distribution to some extent and often learning the distribution incurs some cost.
Problem. The ski-rental problem is studied in this framework. The problem is as follows: Ann wants to go skiing, but she does not know the exact number of days she would like to ski. Each morning she has to decide if she has to rent a pair of skis or buy them. Renting the skis cost 1 unit/day and buying them would cost b units. The goal is to minimize the total cost.
Here is a trivial 2-competitive algorithm: Rent the skis for b-1 days. If she decides to go on the bth day, then buy them. This is the best one can do in a deterministic setting. The best randomized algorithm gives a competitive ratio of e/(e-1).
Results. Given a desired competitive ratio e/(e-1)+ε, the paper gives lower and upper bounds on the number of queries that need to be asked in order to achieve that ratio. The lower bound is C/ε (where C is a universal constant) and the upper bound is O(1/ε1.5).
Rainbow Connectivity: Hardness and Tractability. Prabhanjan Ananth, Meghana Nasre, and Kanthi K Sarpatwar.
Problem. In an edge-colored graph, a rainbow path is a path in which all the edges have different colors. Given a graph G, can we color the edges using k colors such that every pair of vertices has a rainbow path between them? In short, is rc(G) ≤ k? A graph is said to be rainbow connected if the above condition is satisfied. Further, for every pair, if one of the shortest paths between them is a rainbow path, then the graph is said to be strongly rainbow connected (src(G)).
Results.The paper shows that determining if src(G) ≤ k is NP-hard even for bipartite graphs. The hardness of determining if rc(G) ≤ k was open for the case when k is odd. The authors establish the hardness for this case (for every odd k≥3) by an indirect reduction from vertex coloring problem. The argument is combinatorial in nature. I’m not sure if the same argument can be tweaked for the case when k is even (which might simplify the overall proof of hardness for every k≥3.)
Simultaneously Satisfying Linear Equations Over F2. (by Robert Crowston et. al)
Problem. We are given a set of m equations containing n variables x1,…,xn of the form ∏i∈Ixi=b. The xis and b take values from {-1,1}. For example, equations can be x1x4x8=1, x2x5xn=-1, etc. Each equation is associated with a positive weight. The objective is to find an assignment of variables such that the total weight of the satisfied equations is maximized.
The problem is known to be NP-Hard, so we concentrate on a special case. Let the total weight of all the equations be W. If we randomly assign 1 or -1 to each variable, every equation gets satisfied with probability 1/2. Hence, there is always an assignment that is guaranteed to give a weight of W/2. The problem MAX-LIN[k] is to find the complexity of finding an assignment with weight W/2+k, where k is the parameter.
Roughly, a problem is said to be fixed-parameter-tractable (FPT) is if an input instance containing n input bits and an integer k (called the parameter) can be solved in time f(k)nO(1), where f(k) depends only on the parameter k.
Results. The authors show that the problem MAX-LIN[k] is FPT and admits a kernel of size O(k2 log k) and give an O(2O(klog k)(nm)c) algorithm. They also have new results for a variant of the problem where the number of variables in the equation is fixed to a constant. The results in the paper is built on the previous results by the same authors some parts of which use Fourier analysis of pseudo-Boolean functions. I’m not familiar with these techniques.
Obtaining a Bipartite Graph by Contracting Few Edges. (by Pinar Heggernes et. al)
Problem. Given a graph G, can we obtain a bipartite graph by contracting k edges? This problem though simple to state was not studied before. Which is quite surprising considering that the related problem of removing vertices to obtain a bipartite graph is a central problem in parametrized complexity.
Results. The main result of the paper shows that the problem is fixed-parameter-tractable when parametrized by k. The result makes use of many techniques well-known in parametrized complexity like iterative compression, irrelevant vertex and important separators. An interesting open question is to decide if the problem admits a polynomial kernel.
The update complexity of selection and related problems. (Manoj Gupta, Yogish Sabharwal, and Sandeep Sen)
Problem. We want to compute the function f(x1,x2,…,xn) when the xis are not known precisely but rather just known to lie in an interval. We are allowed to query and update a particular variable, to get a more refined estimate. Each query has some cost. The objective is to compute the function f with minimum number of queries.
Results. The previous literature focuses on the case when the query returns the exact value of the variable. This paper generalizes the model by allowing query updates that return open or closed intervals or points instead of exact values. The performance of the online algorithm is compared against an offline algorithm that knows the input sequence and therefore is able to ask the minimum number of queries to an adversary. For some selection problems and MST, the authors show that a 2-update competitive ratio holds for the general model.
Optimal Packed String Matching. (by Oren Ben-Kiki et. al)
Problem. Given a text containing n characters find if a string of m characters appears in the text.
Results. This is an age-old problem. The paper considers the packed string matching case where each machine word can hold up to α characters. The paper presents a new algorithm that extends the Crochemore-Perrin constant-space O(n) algorithm to run get an O(n/α) algorithm. Thus achieving a speed-up of factor α. The packed string matching problem is also-well studied. What is different in this paper is that they achieve better running times by assuming two instructions that have become recently available on processors: one is string-matching instruction WSSM which can find a word of size α in a string of size 2α and the other is WSLM instruction which can find the lexicographically maximal-suffix in a word.
Physical limits of communication. (Invited talk by Madhu Sudan)
Given a piece of copper wire, what is stopping us from transmitting infinite number of bits in unit time on it? The is a fundamental question in communication theory. There could be two reasons why the capacity could be unbounded. Firstly, the signal strength is a real value so there are infinite number of them. Secondly, there are infinitely many instances of time at which a signal can be sent. The first possibility is ruled out due to the presence of noise. It appears that the delay in transmission time rules out the second possibility too, but this has not been extensively studied.
This paper studies this problem in a model where the communicating parties can divide the time into any number of slots but have to cope up with (possibly macroscopic) delays. The surprising result is that the capacity of the channel is bounded only when either noise or delay is adversarially chosen. If both the error sources are stochastic (or if noise is adversarial but independent of stochastic delay) then the capacity of the channel is infinite!
There were other invited talks by Susanne Albers, Moshe Vardi, John Mitchell, Phokion Kolaitis and Umesh Vazirani. Unfortunately, I missed many of these talks.
On the lighter side
TCS Crossword
 Try these:
Try these:
- A confluence of researchers that generates fizz? (4)
- Fundamental fight (6,4)
- If the marking is right, it will fire! (8)
Find more clues like these and the grid in the TCS Crossword that was handed out to attendees during a coffee-break.
Algorithmic Contest (for students)
There was an algorithmic-contest as part of the conference (hosted on Algo Muse). Here is a take-away puzzle:
Contiguous t-sum problem. Given an array A[1..n] and a number t as input, find out if there exists a sub-array whose sum is t. For example, if the input is the array shown below and t=8, the answer is YES since A contains the sub-array A[2..4] whose sum is t.Prove an Ω(n log n) lower bound for the above problem on a comparison model.
 Prove an Ω(n log n) lower bound for the above problem on a comparison model.
Prove an Ω(n log n) lower bound for the above problem on a comparison model.Theory Day at Georgia Tech (and also in NYC)
This post is by David Pritchard and Lev Reyzin.
Last Friday (11/11) was Theory Day at Georgia Tech. In fact, it was also Theory Day in NYC, although nobody seems to think the choice of date was coordinated or the start of a new national holiday. In Atlanta, Georgia Tech invited Avi Wigderson to give two talks on Thursday (making for two theory days in a row!), one for the broader public and then a math-on-whiteboard talk in the afternoon; and on Friday, there were four talks: by Thomas Dueholm Hansen, Mohit Singh, Alexander Mądry, and Ryan Williams, all aimed at theoreticians.
Dave: I was pretty impressed by the quality of the talks, which were about an hour long, and therefore gave the speakers quite a good chance to get into a bit of the technical details that are usually skipped at conferences. I have skimmed a couple of the papers before and really got much more intuition with these in-person explanations. Avi’s second talk was probably the most self-contained, on aspects of coding and a generalized Erdős/Gallai/Melchior/Sylvester theorem. Also, we found that Alex may be a pyromaniac, since his examples for the k-server problem involved houses burning down (which you could think of as data requests). I was also pretty impressed by the quality of the lunch, which was a buffet of Indian food.
Lev: While I was a graduate student at Yale and during my year at Yahoo! Research in New York, I attended all the New York Theory Days for 5 years straight, so I was glad to see catch on in Atlanta too. Apparently, we have Zvi Galil (now Georgia Tech’s College of Computing dean) to thank for the ideas of starting both the New York and the Atlanta theory days — so while the dates were not coordinated, the Theory Days, in some sense, were. All four talks were great. I especially enjoyed Alexander Mądry’s great and accessible talk on his recent progress on the k-server conjecture. Ryan Williams also gave a very nice talk on how algorithms for circuits can imply lower bounds; it gave me some intuitive understanding that I didn’t have before. Finally, I should note that I seem to remember the talks being filmed, so I’m hoping the videos will show on on Georgia Tech’s ARC website sometime.
If any readers attended the NYC Theory Day, please share your impressions in the comments!
Midwest Theory Day 2011
I attended the 62nd Midwest Theory Day last Sunday, November 13rd. Usually there are two such theory days each year, but this was the only one in 2011. The event is like an informal workshop: anyone who wishes may sign up to speak, there are also invited speakers, lunch is provided, and there is no proceedings. Nicole Immorlica organized the event, and did a great job: there was a full day of talks, the room was great, the food was as good as any conference I’ve been to, and the invited speakers were entertaining and educational.
Yael Tauman Kalai gave the first invited talk. She gave a high-level overview of some hot topics in cryptography. For example, she provided intuition into results she and co-authors obtained about designing systems whose algorithms resist physical attacks on cryptosystems. A dramatic physical attack is someone who wants to break into a SIM card, so cooks it in a microwave oven for a while; this can cause bits to flip in the secret key, and even modify the circuitry of the SIM card itself. (Some other examples of physical attacks are here.) Tauman Kalai presented a formalism in which the attacker could determine the system’s secret key, but would still be unable to produce a second secret key matching the system’s public key, unless the attacker used exponential resources or broke a reasonable cryptographic assumption. For a system that can defend itself against an adversary capable of obtaining continual memory leakage of the system, see the FOCS 2010 paper Cryptography Resistant to Continual Memory Leakage (co-authors Brakerski, Katz, Vaikuntanathan).
Adam Kalai was the other invited speaker; he provided an overview of his ITCS 2011 paper Compression Without a Common Prior: an Information-Theoretica Justification for Ambiguity in Natural Language (co-authors Juba, Khanna, Sudan). His talk was controversial: quite a few members of the audience either didn’t get his point, or got it and didn’t agree. The idea, as I understand it, is to produce a mechanism two computers can use to compress and decompress messages they send to each other, even if their respective compression dictionaries (or “priors”) are different. The motivation is how natural language works: you and I don’t have the same definitions for all words (and very different life experience) and yet we can communicate pretty well most of the time (for purposes of the example anyway). If the message is large enough, one could of course use an algorithm like Lempel-Ziv, which approches best-possible compression in the limit. But perhaps we just want to send one image, instead of thousands, and we would like to take advantage of the fact that both computers have useful priors for what an image is, even if those priors are not the same. The paper provides an information-theoretic framework for this, but there is, as yet, no implementable algorithm.
There was also a day full of 15- and 20-minute talks by students, postdocs and faculty. I will completely arbitrarily limit myself to the talks of the two people who sat on either side of me at lunch. Fortunately, I thought both their talks were great.
Paolo Codenotti presented some brand new work on the group isomorphism problem: Polynomial-Time Isomorphism Test for Groups with no Abelian Normal Subgroups (co-authors Babai, Qiao). This work extends the SODA 2011 paper Code Equivalence and Group Isomorphism (co-authors Babai, Grochow, Qiao). The problem solved is the following: let $latex G$ be a group on $latex n$ elements, given to us as its multiplication table of size $latex n^2$. Let $latex H$ be another group on $latex n$ elements, given in the same way. If we know that $latex G$ and $latex H$ contain no normal subgroups that are abelian (i.e., commutative), then we can determine whether $latex G$ and $latex H$ are isomorphic in polynomial time. One example of such a group is $latex A_5$, the alternating group on 5 elements, which has order $latex n=60$. Another example would be any group built from direct sums of copies of $latex A_5$.
Tyson Williams gave an overview of his ITCS 2011 paper, Gadgets and Anti-Gadgets Leading to a Complexity Dichotomy (co-authors Cai, Kowalczyk). Williams has also posted his slides from this talk online. This paper is in the general category of holographic algorithms, a remarkable subfield of counting complexity started by Les Valiant and explored by Jin-Yai Cai, Williams’s advisor. Since the slides are online, and the intuition behind the paper’s approach is so visual, I will let the slides speak for themselves, and close this post by simply stating the paper’s main theorem.
Theorem. Over 3-regular graphs $latex G$, the counting problem for any binary, complex-weighted function $latex f$, $latex \displaystyle Z(G) = \sum_{\sigma:V \rightarrow \{0,1\}} \prod_{(u,v) \in E} f(\sigma(u),\sigma(v))$ is either polynomial-time computable or #P hard. Furthermore, the complexity is efficiently decidable.
The formalism of $latex f$ captures a wide variety of problems on 3-regular graphs, such as #VertexCover (how many vertex covers are there for the input graph), which is #P hard.
Conference Report: DNA 17
The 17th Conference on DNA Computing and Molecular Programming (DNA 17) was held Sept. 19-23 in Pasadena, California, at Caltech. In previous years the conference was held in early summer, but from now on it will be late summer/early fall in order to stagger 6 months apart from its sister conference FNANO (Foundations of Nanoscience), held every April in Snowbird, Utah.
The conference is not dedicated to theoretical computer science, of course, but like many inter-disciplinary fields such as algorithmic game theory or computational biology, theoretical computer science finds its way into many results in the field. As Luca Cardelli said during the conference, while the computing revolution was about the systematic manipulation of information, nanoscience is about the systematic manipulation of matter, so it is not surprising that theoretical computer scientists are finding interesting problems in this area. I find it fascinating to watch a speaker prove a result relating DNA self-assembly to context-free grammars, just before the next speaker shows atomic force microscopy images of a self-assembled DNA nanostructure.
There’s always some impedance mismatch when experimentalists and theorists in any field get together to talk, but I believe our field promotes excellent cross-communication. The program committee, for instance, had members from the following university departments:
- Biological Chemistry and Molecular Pharmacology (1)
- Computer Science (17)
- Biophysics (1)
- Chemistry (4)
- Mathematics (1)
- Electrical Engineering (3)
- Bioengineering (3)
- Bioinformatics (4)
- Physics (2)
- Computation & Neural Systems (1)
- Cognitive Science (1)
- Systems Biology (1)
Interesting Conference Features
First I want to discuss some interesting features of the conference that I think could be beneficially adopted by general TCS conferences (some of these we are already seeing in TCS). As one of the local organizers, I was partially responsible for implementing some of these ideas, and I think it was worth the effort.
Tutorials
The first day was dedicated to three 90-minute lecture-style tutorials (slides available), and in parallel, there was an all-day wet-lab tutorial run by Elisa Franco, Josh Bishop, and Jongmin Kim,1 in which the students constructed a chemical oscillator based on Jongmin’s and Elisa’s work on constructing chemical oscillators from DNA and transcription enzymes. Most of the tutorial attendees were theoreticians who wanted to see what all the fuss was about in the lab. It seems that about half of the oscillators worked properly on the first try. (They only got one try because the period of the oscillation is a few hours, so they had to run overnight.)
Tracks
One interesting aspect of the conference is the tracks, designed to appeal to both theoretical and experimental researchers. Track A looks familiar to TCS people: 15-page extended abstracts that appear in the conference’s LNCS proceedings. These are usually later submitted to CS journals such as SICOMP or TCS, or perhaps in the special issue of invited papers in Natural Computing associated with the DNA conference. Track B submissions are 1-page abstracts submitted for oral presentation only. Authors must provide a full paper for the program committee to judge, but the paper is not published. This is because Track B submissions are experimental results destined for eventual publication in physical science journals such as Nature, Science, or PNAS. These journals have much stricter requirements than CS journals regarding prior publication, so it is critical to the Track B presenters that nothing they submit can be construed as a publication.
Track C is posters, which are very common at physical science conferences and starting to make some headway at TCS conferences. I think posters are a great way to present your research, and I think the TCS community should adopt poster sessions at every conference. Maybe the person you most wanted to see your talk won’t attend it, but you can always grab them in the hallway and drag them over to your poster. It’s a great way to meet big shots in the field. There were three 90-minute poster sessions, with every poster at every session, and we encouraged the presenters to keep their posters up the whole week. This way, you could stand by your poster for a while, but you could also feel free to walk around to other posters without worrying that someone won’t get a chance to hear you explain your poster while you are away.
Panels
The panels consisted of four top researchers sitting at a table. Each gave a 5 minute talk about their vision for the future of the field, and then the audience could ask questions or heckle them for the next 25 minutes. These were a lot of fun. I think students especially benefited from the perspective given by high-level discussion of long-term research goals.
Impromptu Sessions
The impromptu sessions were a great idea, and I think all conferences could benefit from them. I think of them as a formalization of the idea that “the real conference interaction happens in the hallways” (as Lance Fortnow likes to remind us.) Often graduate students are intimidated by the idea of walking up to a couple of famous big-wigs talking in the hallway, even if they are talking about the student’s research area. For the impromptu sessions, there was a wiki where over the course of the week, anyone could schedule a session on any topic in a number of rooms that were reserved for the sessions. The sessions were required to be public, and I found it to be a great way for people to get together to chat about interesting problems, while inviting anyone else interested in the same problem to listen in or participate.
Theoretical Computer Science Results
I will highlight a few theoretical results that I found interesting. There were of course many great experimental results, and a lot of great CS talks on topics such as simulation, but since this is a TCS blog, I will focus on my favorite TCS-style results.
Self-Assembly and Context-Free Grammars
The winners of the best student paper award were Andrew Winslow and Sarah Eisenstat, for their excellent paper One-Dimensional Staged Self-Assembly, with Erik Demaine and Mashhood Ishaque.2 Fix a finite alphabet $latex \Sigma$ and a finite set $latex G$ of “glues”. A tile type is a square labeled with a symbol from $latex \Sigma$, with its east and west sides labeled with (different) glues from $latex G$ (such tiles, both 1D and 2D, can be experimentally implemented with DNA). Initially all tile types start in separate test tubes. When two test tubes are mixed, any tile can bind to the west of any other tile if the first tile’s east glue matches the second tile’s west glue. Subsequent mixing may bind whole rows of tiles together. After each mixing, it is assumed that individual tiles are washed away so that only terminal assemblies (assemblies that cannot attach to anything else in the tube) remain.
The goal: design a fixed set of tile types so that any string over $latex \Sigma$ can be “spelled” by efficiently mixing the tiles in the correct order. How efficiently? The authors show that if each intermediate test tube is required to contain only one terminal assembly, then the number of mixing stages required to spell the string $latex x$ is within a constant multiplicative factor of the smallest context-free grammar that produces the singleton language $latex \{x\}$ (and they show that this bound is tight).
What does this mean? There is a linear-time $latex O(\log n)$-approximation algorithm for finding the smallest context-free grammar representing a string in this way (due to Sakamoto), which automatically translates to a linear-time algorithm for finding efficient mixing protocols for self-assembling one-dimensional patterns (implemented by the authors; here is an efficient mixing to spell the final verse of Edgar Allen Poe’s “The Raven” with DNA tiles).
However, if intermediate mixing stages are allowed to contain multiple terminal assemblies, even though the final stage is required to have only one terminal assembly (the assembly spelling $latex x$), then the number of mixing stages can be dramatically reduced (by a multiplicative factor of at least $latex \frac{n}{\log n}$).
Fuel-Efficient Computation with DNA Strand Displacement
My favorite paper was Less Haste, Less Waste: On Recycling and its Limits in Strand Displacement Systems, by Anne Condon, Alan Hu, Jan Manuch and Chris Thachuk. There has been a flurry of experimental and theoretical papers in the past few years based on a technique known as DNA strand displacement. It was shown by Soloveichik, Seelig, and Winfree that arbitrary chemical reactions can be “implemented” by DNA using the strand displacement reaction.3 Non-mass-conserving reactions such as $latex A \to A + B$ are implemented by extra “fuel” species assumed to be in abundance, so that the underlying implementation of $latex A \to A + B$ would consume fuel molecules and produce waste molecules, none of which corresponds to the abstract species $latex A$ or $latex B$.
Anne, Alan, Jan, and Chris showed how to implement a simple and pervasive computation — a counter that iterates through $latex 2^n$ different states using $latex O(n)$ different species — while consuming only $latex O(n^3)$ total fuel molecules (and producing the same amount of total waste molecules). A naïve implementation would consume fuel at every step, using $latex \Omega(2^n)$ fuel.
However, their counter requires that certain species have exactly one molecule present in solution, a tall order to implement experimentally. A more robust counter would work even with many copies of each species present, i.e., if many counters were thrown in together, they would each independently iterate from $latex 1$ to $latex 2^n$, without interfering with each other.
My favorite theorem in the paper shows this task to be impossible.4 In particular, they show a contrapositive result: any chemical reaction system (not just those implemented by DNA strand displacement) with $latex n$ species that is tolerant to having many copies of the system all reacting at once, has the property that any species is producible after $latex O(n^2)$ steps. In other words, if there is some species $latex S_{\text{end}}$ whose presence signifies the “end” of computation, there is no way to deterministically visit more than quadratically many states that do not contain a copy of $latex S_{\text{end}}$.
As an example, if we wanted to implement a chemical system simulating an $latex O(n^3)$-time Turing machine with only $latex O(n)$ species,5 it could not possibly work unless some species are present in small quantities; i.e., multiple copies of the system would provably interfere with each other if placed in the same test tube.
While this is not a complexity theory result (telling us nothing about the relationship between $latex \mathsf{P}$ and $latex \mathsf{NP}$, for instance), nor did they use any classical complexity theorems such as the time hierarchy theorem, nonetheless, only a complexity theorist would even think to conjecture such a statement about chemistry. This is why TCS is often needed to study molecular systems.
Optimal Tile Sets for Self-Assembly of Patterns
The paper Synthesizing Small and Reliable Tile Sets for Patterned DNA Self-Assembly, by Tuomo Lempiäinen, Eugen Czeizler and Pekka Orponen, attacks a variant of a problem in the abstract tile assembly model that has annoyed me for many years. The problem is: given a $latex k$-coloring of an $latex m \times n$ rectangle, find the smallest tile set $latex T$ such that, if each tile type is colored appropriately, $latex T$ self-assembles an $latex m \times n$ rectangle with the given coloring.
In their variant of the problem, the rectangle grows “rectilinearly” from an L-shaped “seed”, where all tiles attach via their west and south glues, and both glues must match for them to attach. The authors use heuristics combined with an exponential-time branch-and-bound search algorithm to find small (not necessarily minimal) tile sets.
They also analyze the reliability of the tiles in the face of errors (tiles attaching by only a single matching glue at some small rate $latex \varepsilon$), finding that the tile sets their algorithm produces become more reliable on average, the longer the algorithm runs before manual termination.
In one well-characterized variation of this problem, the input is a shape $latex S$ rather than a coloring, and the question is what is the smallest tile set that is guaranteed to place tiles on exactly the points in $latex S$. If we require only one terminal assembly, the problem is $latex \mathsf{NP}$-complete (see here). If we allow multiple terminal assemblies, but require that they all have the shape $latex S$, then the problem is $latex \mathsf{NP^{NP}}$-complete (see here).
I strongly suspect that the pattern version of the problem is $latex \mathsf{NP}$-complete (and variants of it, say, if the tiles grow from a single seed tile, or if they are merely required to stay inside the $latex m \times n$ rectangle but do not have to fill the whole rectangle). However, the main technique for the hardness results on shapes crucially use the fact that optimal tile sets for tree shapes are very well-characterized (and can be computed in polynomial time, see here). These techniques do not seem to work at all with patterns. I would be very excited by any progress on hardness results for this question.
Universal Computation at Temperature 1 with a Negative Glue
The paper Exact Shapes and Turing Universality at Temperature 1 with a Single Negative Glue, by Matt Patitz, Robbie Schweller and Scott Summers, attacks another problem in the abstract tile assembly model that has annoyed me for many years; it is the first problem I worked on in self-assembly.
Cooperative binding in tile assembly refers to the requirement that a tile with two strength-1 glues cannot attach to an assembly unless both glues match the assembly. So-called “temperature 1” self-assembly models the situation in which all individual glues have sufficient strength to bind tiles stably, so that cooperative binding cannot be enforced. We conjectured that universal computation (e.g., the ability to simulate a Turing machine) in self-assembly requires cooperative binding. This is known to be false in 3D, but the proof crucially uses the third dimension to allow tiles to “escape” a closed region in one plane by growing into the adjacent plane. In a planar self-assembling system, deterministic computation seems very difficult to do, but proving its impossibility is an open problem.
Matt, Robbie, and Scott show that temperature 1 universal computation is possible if we introduce negative glues. Specifically, they need only introduce one single type of negative glue, so we could imagine it being implemented, for instance, by magnets that repulse any other copy of the glue.6 Essentially, the negative glue is put in place where cooperation is desired in advance of any neighboring positive-strength glues, guaranteeing that by the time any tile could bind, it must bind to 2 positive strength glues to overcome the repulsive force of the negative glue already present. With this cooperation comes universal computation, the ability to assemble large structures (e.g., $latex n \times n$ squares) from a small ($latex \frac{\log n}{\log \log n}$) number of tile types, and other hallmarks of the computational power of cooperative binding.
But the original question stands: what is the computational power of deterministic, planar, positive-strength, temperature 1 self-assembly? Is cooperative binding truly necessary to compute by planar self-assembly?
Future DNA Conferences
Next year, the DNA conference will be at Aarhus University in Denmark, hosted by Kurt Gothelf. The following year, it will be held at Arizona State University, hosted by Hao Yan. To avoid instances of heat stroke in Tempe, Arizona, the conference will likely be later in the fall, but that is yet to be determined. I hope to see you there!
Footnotes
1 Jongmin’s web presence, like many experimentalists, is minimal.
2 Erik and Mashhood are not students. Since almost all experimental papers have the lab PI as last author, to avoid automatically excluding students in experimental labs, the DNA conference allows the best student paper award to go to papers with non-student authors, as long as a student is the main author and the PI writes a letter of support stating this.
3 i.e., you can write down a list of chemical reactions such as $latex A + B \to C + D, C + X \to C + Y, \ldots$, and you can give them as input to a compiler that will output a list of DNA complexes, some of which correspond to the abstract chemical species $latex A,B,C,X,Y,\ldots$, and the dynamic evolution of the DNA concentrations will mimic that described by the abstract reactions.
4 I love impossibility results. My experimentalist friends call me “depressing”.
5 If the Turing machine uses linear space, this is easy to implement if single-copy molecules are allowed, by having a constant number of species for each tape cell to represent its symbol and, if the tape head is there, the current state.
6 There has been some work (here and here) attaching magnets to DNA, so this is not an infeasible idea.
Conference Reports: EuroComb, Katona 70, ESA
From August 28 to September 7 I participated in the following three meetings:
- The 6th EuroComb, in Budapest. This conference happens every 2nd year. There were 5 days, 4 parallel sessions, and discrete mathematics of every flavour, especially graphs, randomness, geometry, set systems, and algorithms.
- Gyula Katona’s 70th birthday conference, also in Budapest at the Renyi institute.
- The 19th European Symposium on Algorithms, in Saarbrucken. This was 3 days, with 2 parallel sessions plus more for satellite conferences, and the algorithmic topics included approximation algorithms, parameterized complexity, strings, geometry, graphs, SAT, and practical experimental work.
- (Saarbrucken continued with two more days of the ALGO meta-conference, including ATMOS, WAOA, IPEC, and AlgoSensors. I usually attend WAOA, but this year after seeing about 80 talks in 10 days, I left for home.)
EuroComb
Here is a little bit of info about the conference. EuroComb has a small level of refereeing, allowing people to present anything, including results already published elsewhere. It was a very social conference, and this reminded me of other rarer-than-annual conferences like ISMP and CANADAM. You get to meet many people, and they generally present their best recent results, which I liked. There were a lot of people of PhD/PostDoc age but also a lot of professors, and there were participants from all over the world. (It was even a nice chance for me to make a few new acquaintances from Canadian universities.) I talked about a paper in the realm of discrete geometry that used computational methods, joint with Filip Morić.
One major plenary was given by Nets Hawk Kats. He and Larry Guth recently solved* Erdős’ distinct distances problem: show that for any n points in the plane, the number of distinct distances among these points is at least Ω(n/√log n). The * is because they only got Ω(n/log n), still it improves polynomially on all previous bounds. I have heard some discussion of the result and its proof, overall it is elegant, although the talk was not well-prepared.
In more algorithmic news, Dan Král won a major award and his plenary talk was mostly about his work on fast algorithms for variants of small-treewidth problems, extending Courcelle’s work on FOL/MSOL languages expressing very general problems that can be solved in such families. David Conlon also won the same award, and his talk was about better understanding of the tower and “wowzer” functions arising in proofs of the Szémeredi Regularity Lemma and relatives (e.g., the Graph Removal Lemma). I learned that while the tower function is T(k) = 2^(2^…^(2^2)…) where k 2’s appear, the wowzer function is W(k) = T(T(…T(2)…)) where there are k T’s.
Several interesting open problems arose at EuroComb, and here is one of them. The rainbow colouring number of a graph is the minimum number of colours one needs to apply to the edges, so that all pairs of vertices are connected by a rainbow path (no repeated colours). Is there a constant-factor approximation for the rainbow connection number? The concept was defined only a few years ago but there have been an explosive number of papers on the topic.
Another highlight: Ken-ichi Kawarabayashi put his cat on one of his slides.
Katona 70
There is a strong tradition of birthday conferences for researchers in Budapest and apparently Gyula Katona was even one of the forces behind this tradition; his friends had a lot of very nice things to say and presents to give him. For example, he received an Indian decoration usually reserved for elephants. He is perhaps most famous for the Kruskal-Katona theorem and indeed, the majority of talks were about extremal problems in hypergraphs. My former EPFL colleague Dömötör Pálvölgyi gave a very entertaining talk about determining max/min elements with a lie: it takes about n*87/32 queries and this crazy number is tight. From another talk by Alex Sidorenko I learned a nice trick which gave me some intuition about “virtual valuations” in algorithmic game theory, which I have posted on my blog.
ESA
This is my 4th year in a row attending ESA, and it is one of my favourite conferences because many talks are about work that can be explained to a general algorithmic audience. This year, for the first time, they have given each person a USB key with electronic proceedings, which are truly awesome; not simply a .pdf dump, but a fantastic browser-navigable html/pdf hybrid.
The best paper went to Nikhil Bansal and Joel Spencer for work on a deterministic version of Spencer’s “6 Standard Deviations Suffice” work on discrepancy. This is the 2nd year in a row the best paper went to an approximation-algorithms paper, which may not be so much of a surprise given that it’s also the 2nd year in a row it went to a paper co-authored by Nikhil.
 The business meeting was unusual, despite (unlike some previous years) the absence of beer. There was one serious proposal for ESA 2013, in Sophia-Antipolis, France, and one half-joking proposal in Muscat, Oman. The presenter of the latter moved there last week and basically just wanted to ensure there was some “choice” for the voters (he admitted as much and also had no price estimates). The constituency picked France over Oman by a 33-22 vote but I would not say it was a close call as everyone could see how everyone voted and some people seemed to vote just to make the vote closer. I’m not sure if it was a useful exercise since it made the business meeting non-trivially longer. It is hard to find people willing to host conferences and I am glad the final result was the one I preferred. Vive là France!
The business meeting was unusual, despite (unlike some previous years) the absence of beer. There was one serious proposal for ESA 2013, in Sophia-Antipolis, France, and one half-joking proposal in Muscat, Oman. The presenter of the latter moved there last week and basically just wanted to ensure there was some “choice” for the voters (he admitted as much and also had no price estimates). The constituency picked France over Oman by a 33-22 vote but I would not say it was a close call as everyone could see how everyone voted and some people seemed to vote just to make the vote closer. I’m not sure if it was a useful exercise since it made the business meeting non-trivially longer. It is hard to find people willing to host conferences and I am glad the final result was the one I preferred. Vive là France!
From a technical perspective, I really liked a few talks in different areas:
- a result about MAX-SAT (out of 5 total in ALGO!) by Roth, Azar, and Gamzu since it showed naturally a matroid arising out of nowhere,
- a constructive algorithm for “ray shooting depth” by Ray (who gave the talk and avoided making the obvious joke), Mustafa, and Shabbir, which is a plane geometry problem which previously had only a non-constructive topological proof,
- the best student paper which was by Gawrychowski on text searching in compressed files,
- a paper by Verschae and Wiese about scheduling unrelated machines, giving an elegant integrality gap construction and a simpler version of an existing algorithmic result from FOCS 2009,
- nice approximation results in a model of graph vehicle routing by Schupbach and Zenklusen,
- a talk by Justin Ward (joint w/ Feldman, Naor, Schwartz) explaining/improving many local search algorithms… for me it finally made clear what’s special about claw-free graphs.