![]()
I attended the FSTTCS conference that was held in IIT Bombay last December. The conference saw over 180 participants and had many interesting talks. I will discuss a few of them in this post.
Talks from Breakthroughs in TCS workshop
Madhu Sudan. Multiplicity Codes: Locality with High Efficiency.
Madhu Sudan gave a nice talk based on a recent result by Swastik Kopparty, Shubhangi Saraf and Sergey Yekhanin (STOC 2011). He was excited about the result for two reasons. Firstly, unlike other advances in LDCs where applications of the results are found only in other parts of theory, this result actually could be of great practical interest. “It’s the numbers that are making sense” he said. Secondly, the construction of the code is so elegant that you are surprised by its simplicity.
I’ll try to sketch the main idea below:
Background. Suppose we want to send a k-bit message on a noisy channel. A well-known method is to use an error-correcting code to encode the k-bit message x into an n-bit codeword C(x) and transmit the codeword instead of the message x. The codeword C(x) is such that we can recover the original message x from it even if many bits in C(x) get corrupted. A typical way to recover x would be to run a decoder on the (possibly corrupted) C(x).
Two parameters in this scheme are of interest: the redundancy incurred in constructing the codeword C(x) and the efficiency with which we can decode the message x from the codeword. The complexity of encoding is usually ignored since it is not critical in most applications.
The rate of the code is the ratio of message length to codeword length: k/n. The higher the rate, the lesser the redundancy of the code.
LDCs. But what if one is interested only in knowing just a particular bit of the message x? This is where a Locally Decodable Code (LDC) is useful. LDCs allow the reconstruction of any arbitrary bit xi by looking only at a small number of randomly chosen positions of the received codeword C(x). The query complexity of the code is the number of bits we need to look at in order to recover a particular bit.
Obviously, we desire to have LDCs with high rate and low query complexity. But until now, for codes with rate>1/2, it was unknown how to construct any non-trivial decoding. For rates lower than 1/2, we could construct a code with rate O(εΩ(1/ε)) and query complexity O( kε) for 0<ε<1. For example, Reed-Muller codes — which are based on evaluating multivariate polynomials.
Bivariate Reed-Muller codes. We briefly describe how polynomials can be useful in coding. Let Fq denote the finite field of cardinality q. Consider the bivariate polynomials over the field Fq. A bivariate polynomial of degree d has ( {d+1 \choose 2} ) monomials. For example, if d=2 the monomials are x2,xy and y2. So any polynomial of degree d can be specified by the coefficients of each of these monomials. The coordinates of the message x can be thought of as coefficients of a polynomial P(x,y) of degree d. So our message is of length ( k={d+1 \choose 2} ). Each coordinate of the message has a value from Fq (we call this an alphabet). The codeword C(x) corresponding to the message x is obtained as follows: The coordinates of the codeword is indexed by elements of ( F_{q}^2 ). So the length of the codeword n=q2.
The codeword corresponding to the polynomial P(x,y) is the vector C(P) as given below:
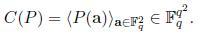
So the first co-ordinate of C(P) would have the value of P(1,1), the second coordinate would have the value of P(1,2), and in general the (i*q+j)th coordinate of C(P) would have the value P(i,j).
The rate of this code is less than 1/2 and it can be shown that the correct value at a particular coordinate of the received codeword can be decoded by making only O(√k) queries on the received codeword, assuming that a constant fraction of the codeword gets corrupted.
Multiplicity codes. The key idea in the paper is to encode the message using multivariate polynomials and their partial derivatives. If we plug this idea to the above example, each coordinate of the codeword will have 3 alphabets instead of one or in other words each coordinate would be a value from ( F_{q}^3 ). So the codeword is now:
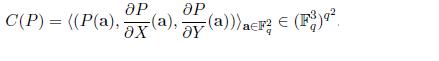
This improves the rate from <1/2 to 2/3! It can be done without increasing the query complexity. This by itself is a new result. What’s more is they can extend this idea to get codes of arbitrarily high rate while keeping the query complexity small. Here is their main theorem from the paper:
For every ε>0, α>0, and for infinitely many k, there exists a code which encodes k-bit messages with rate 1-α, and is locally decodable from some constant fraction of errors using O(kε) time and queries.
Umesh Vazirani. Certifiable Quantum Dice.
Background. Many computational tasks such as cryptography, game theoretic protocols, physical simulations, etc. require a source of independent random bits. But constructing a truly random device is a hard task. Even assuming that such a device is available, how do we test if it is working correctly? This task seems impossible since a perfect random number generator must output every n bit sequence with equal probability and there is no reason one can reject a particular output in favor of an other.
Quantum mechanics offers a way to get past this fundamental barrier: starting with O(log2 n) random bits one can generate n certifiable random bits.
To get an idea of how this is possible let us consider the CHSH game first (given below).
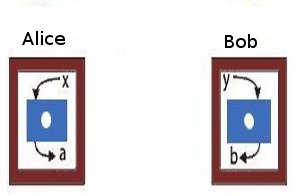 |
| The CHSH game. Alice and Bob are two co-operating players who receive inputs x and y, respectively from a third party. Alice and Bob are at two different locations. The winning condition for them is to produce outputs a and b such that the following condition is satisfied: If x=y=1, then a and b must be different. For any of the other three combinations of x and y, the outputs have to be equal. If the players are correlated according to the laws of classical physics, only any three of the four pairs of inputs can be satisfied. So the maximum probability of winning is 0.75. However, if they adopt a strategy based on quantum correlations, this value can be increased to 0.851. See the references in this article in Nature for more details. |
We can define a quantum regime corresponding to the success probabilities between 0.75 and 0.85. It is simple to construct two quantum devices corresponding to any value in the regime. But if two devices produce co-relations in the regime, they must be randomized. Or in other words, randomness is for real! This gives a simple statistical test to cerfify randomness.
Result. We are using two random input bits (x,y) to produce two random output bits, so this doesn’t accomplish much. We cannot claim the output to be more random than the input. Vazirani and Vidick in their paper describe a protocol that uses O(log 2 n) seed bits to produce n certifiable random bits.
Jaikumar Radhakrishnan. Communication Complexity of Multi-Party Set-Disjointness Problem.
Consider the following problem: Alice and Bob are given inputs x and y respectively and are asked to compute a function f(x,y). They are charged for the number of bits exchanged. The minimum number of bits that have to be exchanged in order to compute the function f is the communication complexity of the problem. A particular problem that is of interest in the area of communication complexity is the set-disjointness problem.
Problem. There are k parties each of whom has a subset from {1,..,n} stuck on his forehead. Each party can see the all the subsets except his own. The set-disjointness problem is to determine if the intersection of all the k subsets is empty. Again, we charge for the number of bits exchanged. All the parties have access to a shared blackboard on which they can write, so we have a broadcast medium.
The case when k=2 is well-understood both in both deterministic and randomized settings. (In randomized version, all the parties have access to a shared source of infinite random bits.)
Results. Until recently, for the general multi-party case, the best lower bound on communication complexity known for the number-on-the-forehead model was Ω(n1/k+1/2k^2). Last year, Sherstov improved this bound to Ω(n/4k)1/4 which is close to tight.
Jaikumar is a fantastic teacher. In what was basically a blackboard-talk, he gave an overview of the main ideas in Sherstov’s proof in a way that was accessible even to non communication-complexity experts. The arguments are based on approximating Boolean functions by polynomials.
Other talks in BTCS
There were several other good talks. Naveen Garg surveyed the recent progress on approximation algorithms for the Traveling Salesman Problem that achieve a strictly better than 1.5 approximation factor. Manindra presented the result on lower bound on ACC by Ryan Williams. Aleksender Madry gave two talks: one in which he presented a new randomized algorithm for the k-server problem that achieves poly-logarithmic competitiveness and one on approximating max-flow in capacitated, undirected graphs using the techniques from electrical flows and laplacian systems. Nisheeth Vishnoi discussed new algorithms for the Unique Games Conjecture. Amit Kumar gave a talk about a recent result by Friedman, Hansen and Zwick on proving lower bounds for randomized pivoting rules in simplex algorithm. Sanjeev Khanna spoke about some recent progress on the approximability of the edge-disjoint paths problem. Most of these results are now famous in theory-circles.
Conference talks
There were 38 papers out of which about 16 were from Theory A. Here are some of the talks I attended:
The Semi-stochastic Ski-rental Problem. (Aleksander Mądry and Debmalya Panigrahi)
An online algorithm is an algorithm which optimizes a given function when the entire input in not known in advance, but is rather revealed sequentially. The algorithm has to make irrevocable choices about the output as the input is seen. The ratio of the performance of the online algorithm to the optimal offline algorithm is called the competitive ratio of the algorithm.
On one hand, we have online models which assume nothing about the input and on the other we have stochastic models which assume that the input comes from a known distribution. The semi-stochastic model in this paper unifies these two extremes. In this model, the algorithm does not know the input distribution initially, but can learn the distribution by asking queries. The algorithm has a certain query budget. If the budget is zero (resp. infinite), the model reduces to the online (resp. stochastic) version. The goal is to maximize the competitive ratio assuming that the queries are answered adversarially.
This model is well-motivated because in many real world situations, the online model is too pessimistic and the stochastic model is too optimistic. We can usually learn the input distribution to some extent and often learning the distribution incurs some cost.
Problem. The ski-rental problem is studied in this framework. The problem is as follows: Ann wants to go skiing, but she does not know the exact number of days she would like to ski. Each morning she has to decide if she has to rent a pair of skis or buy them. Renting the skis cost 1 unit/day and buying them would cost b units. The goal is to minimize the total cost.
Here is a trivial 2-competitive algorithm: Rent the skis for b-1 days. If she decides to go on the bth day, then buy them. This is the best one can do in a deterministic setting. The best randomized algorithm gives a competitive ratio of e/(e-1).
Results. Given a desired competitive ratio e/(e-1)+ε, the paper gives lower and upper bounds on the number of queries that need to be asked in order to achieve that ratio. The lower bound is C/ε (where C is a universal constant) and the upper bound is O(1/ε1.5).
Rainbow Connectivity: Hardness and Tractability. Prabhanjan Ananth, Meghana Nasre, and Kanthi K Sarpatwar.
Problem. In an edge-colored graph, a rainbow path is a path in which all the edges have different colors. Given a graph G, can we color the edges using k colors such that every pair of vertices has a rainbow path between them? In short, is rc(G) ≤ k? A graph is said to be rainbow connected if the above condition is satisfied. Further, for every pair, if one of the shortest paths between them is a rainbow path, then the graph is said to be strongly rainbow connected (src(G)).
Results.The paper shows that determining if src(G) ≤ k is NP-hard even for bipartite graphs. The hardness of determining if rc(G) ≤ k was open for the case when k is odd. The authors establish the hardness for this case (for every odd k≥3) by an indirect reduction from vertex coloring problem. The argument is combinatorial in nature. I’m not sure if the same argument can be tweaked for the case when k is even (which might simplify the overall proof of hardness for every k≥3.)
Simultaneously Satisfying Linear Equations Over F2. (by Robert Crowston et. al)
Problem. We are given a set of m equations containing n variables x1,…,xn of the form ∏i∈Ixi=b. The xis and b take values from {-1,1}. For example, equations can be x1x4x8=1, x2x5xn=-1, etc. Each equation is associated with a positive weight. The objective is to find an assignment of variables such that the total weight of the satisfied equations is maximized.
The problem is known to be NP-Hard, so we concentrate on a special case. Let the total weight of all the equations be W. If we randomly assign 1 or -1 to each variable, every equation gets satisfied with probability 1/2. Hence, there is always an assignment that is guaranteed to give a weight of W/2. The problem MAX-LIN[k] is to find the complexity of finding an assignment with weight W/2+k, where k is the parameter.
Roughly, a problem is said to be fixed-parameter-tractable (FPT) is if an input instance containing n input bits and an integer k (called the parameter) can be solved in time f(k)nO(1), where f(k) depends only on the parameter k.
Results. The authors show that the problem MAX-LIN[k] is FPT and admits a kernel of size O(k2 log k) and give an O(2O(klog k)(nm)c) algorithm. They also have new results for a variant of the problem where the number of variables in the equation is fixed to a constant. The results in the paper is built on the previous results by the same authors some parts of which use Fourier analysis of pseudo-Boolean functions. I’m not familiar with these techniques.
Obtaining a Bipartite Graph by Contracting Few Edges. (by Pinar Heggernes et. al)
Problem. Given a graph G, can we obtain a bipartite graph by contracting k edges? This problem though simple to state was not studied before. Which is quite surprising considering that the related problem of removing vertices to obtain a bipartite graph is a central problem in parametrized complexity.
Results. The main result of the paper shows that the problem is fixed-parameter-tractable when parametrized by k. The result makes use of many techniques well-known in parametrized complexity like iterative compression, irrelevant vertex and important separators. An interesting open question is to decide if the problem admits a polynomial kernel.
The update complexity of selection and related problems. (Manoj Gupta, Yogish Sabharwal, and Sandeep Sen)
Problem. We want to compute the function f(x1,x2,…,xn) when the xis are not known precisely but rather just known to lie in an interval. We are allowed to query and update a particular variable, to get a more refined estimate. Each query has some cost. The objective is to compute the function f with minimum number of queries.
Results. The previous literature focuses on the case when the query returns the exact value of the variable. This paper generalizes the model by allowing query updates that return open or closed intervals or points instead of exact values. The performance of the online algorithm is compared against an offline algorithm that knows the input sequence and therefore is able to ask the minimum number of queries to an adversary. For some selection problems and MST, the authors show that a 2-update competitive ratio holds for the general model.
Optimal Packed String Matching. (by Oren Ben-Kiki et. al)
Problem. Given a text containing n characters find if a string of m characters appears in the text.
Results. This is an age-old problem. The paper considers the packed string matching case where each machine word can hold up to α characters. The paper presents a new algorithm that extends the Crochemore-Perrin constant-space O(n) algorithm to run get an O(n/α) algorithm. Thus achieving a speed-up of factor α. The packed string matching problem is also-well studied. What is different in this paper is that they achieve better running times by assuming two instructions that have become recently available on processors: one is string-matching instruction WSSM which can find a word of size α in a string of size 2α and the other is WSLM instruction which can find the lexicographically maximal-suffix in a word.
Physical limits of communication. (Invited talk by Madhu Sudan)
Given a piece of copper wire, what is stopping us from transmitting infinite number of bits in unit time on it? The is a fundamental question in communication theory. There could be two reasons why the capacity could be unbounded. Firstly, the signal strength is a real value so there are infinite number of them. Secondly, there are infinitely many instances of time at which a signal can be sent. The first possibility is ruled out due to the presence of noise. It appears that the delay in transmission time rules out the second possibility too, but this has not been extensively studied.
This paper studies this problem in a model where the communicating parties can divide the time into any number of slots but have to cope up with (possibly macroscopic) delays. The surprising result is that the capacity of the channel is bounded only when either noise or delay is adversarially chosen. If both the error sources are stochastic (or if noise is adversarial but independent of stochastic delay) then the capacity of the channel is infinite!
There were other invited talks by Susanne Albers, Moshe Vardi, John Mitchell, Phokion Kolaitis and Umesh Vazirani. Unfortunately, I missed many of these talks.
On the lighter side
TCS Crossword
 Try these:
Try these:
- A confluence of researchers that generates fizz? (4)
- Fundamental fight (6,4)
- If the marking is right, it will fire! (8)
Find more clues like these and the grid in the TCS Crossword that was handed out to attendees during a coffee-break.
Algorithmic Contest (for students)
There was an algorithmic-contest as part of the conference (hosted on Algo Muse). Here is a take-away puzzle:
Contiguous t-sum problem. Given an array A[1..n] and a number t as input, find out if there exists a sub-array whose sum is t. For example, if the input is the array shown below and t=8, the answer is YES since A contains the sub-array A[2..4] whose sum is t.Prove an Ω(n log n) lower bound for the above problem on a comparison model.
 Prove an Ω(n log n) lower bound for the above problem on a comparison model.
Prove an Ω(n log n) lower bound for the above problem on a comparison model.Filed under Conference/Workshop Reports
Tagged: codes, communication complexity, FSTTCS, Quantum Computing
Subscribe to comments with RSS.
Comments have been closed for this post